Method
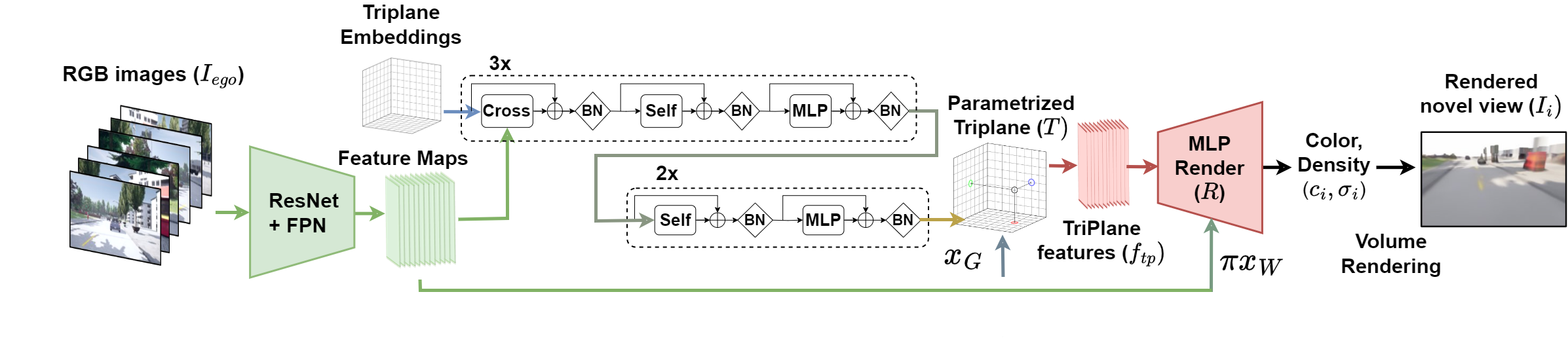
The pixel-aligned image features from the six outward-looking images are indivually extracted using a pre-trained ResNet-101 followed by a Feature Pyramidal Network (FPN). The features are then projected into a triplane using deformable attention. The renderer is a shallow MLP, which takes the triplane latent 3D features concatenated to the corresponding 2D image features, obtained by projecting the 3D coordinates into the 2D image space. The renderer outputs the color and opacity of the 3D features. The color and opacity are then used to render the 3D features into the 2D image space, using volumetric rendering. The rendered 2D images are then used to compute the loss, which is backpropagated through the entire network. The entire network is trained end-to-end.
In order to further improve the quality of the rendered images and speed up the inference, the images are rendered at a lower resolution and then upsampled using SwinFIR.
Results
| Method | PSNR ↑ | SSIM ↑ | LPIPS ↓ |
|---|---|---|---|
| PixelNeRF | 15.263 | 0.695 | 0.673 |
| w/o Scene Contraction | 17.493 | 0.726 | 0.479 |
| w/o LPIPS Loss | 18.953 | 0.736 | 0.538 |
| w/o Image Feature Proj. | 18.440 | 0.726 | 0.488 |
| w SwinFIR Upscaler | 19.188 | 0.746 | 0.444 |
| 6Img-to-3D (Ours) | 18.864 | 0.733 | 0.453 |


















































































{kind=link}